HDF5 as a zero-configuration, ad-hoc scientific database for Python
Andrew Collette, Research Scientist with IMPACT, HDF Guest Blogger "...
March 25, 2015
0
Andrew Collette, Research Scientist with IMPACT, HDF Guest Blogger "...
The HDF Earth Science Program is well aware of this important legacy. We focus on continuing support of U.S. environmental satellite programs (NASA Earth Observing System and Joint Polar Satellite System, JPSS), on-going quality assurance of the HDF libraries and helping data users access and understand products written in HDF. The HDF-EOS Information Center (#hdfeos) includes code examples in MATLAB, IDL, NCL, and Python, many driven by user questions. The site also provides information on other HDF tools.
The Moderate Resolution Imaging Spectro-radiometer, MODIS, can see the Earth in true color as it appears from the satellite Terra. It also measures an unprecedented number of parameters related to global change including ocean plant life, cloud properties, atmospheric particulates (aerosols) and land surface change. Image courtesy NASA and the MODIS instrument team.
NASA’s decision ensured a role for HDF in Earth Science and set an important precedent. HDF developers, along with the U.S. and other Earth Observing nations, developed a clear distinction between Earth Science Data Objects (grids, swaths, profiles…); the metadata required to describe them; and the HDF objects (datasets, groups, attributes, etc.) that make them up.
The critical realization was that communities like EOS needed conventions for describing Earth Science objects to enable using and sharing those objects. These conventions, termed HDF-EOS, have been used successfully in hundreds of NASA products that can be easily shared among multiple users using standard tools.
Many other Earth Science communities have used the powerful combination of conventions and HDF.

Photo from nasa.gov
Perhaps the original producers of “big data,” the oil & gas (O&G) industry held its eighth annual High-Performance Computing (HPC) workshop in early March. Hosted by Rice University, the workshop brings in attendees from both the HPC and petroleum industries.
Jan Odegard, the workshop organizer, invited me to the workshop to give a tutorial and short update on HDF5.
The workshop (#oghpc) has grown a great deal during the last few years and now has more than 500 people attending, with preliminary attendance numbers for this year’s workshop over 575 people (even in a “down” year for the industry). In fact, Jan’s pushing it to a “conference” next year, saying, “any workshop with more attendees than Congress is really a conference.” But it’s still a small enough crowd and venue that most people know each other well, both on the Oil & Gas and HPC sides.
The workshop program had two main tracks, one on HPC-oriented technologies that support the industry, and one on oil & gas technologies and how they can leverage HPC. The HPC track is interesting, but mostly “practical” and not research-oriented, unlike, for example, the SC technical track. The oil & gas track seems more research-focused, in ways that can enable the industry to be more productive.
I gave an hour and a half tutorial on developing and tuning parallel HDF5 applications, which
| Editor’s Note: Since this post was written in 2015, The HDF Group has developed HDF5 Connector for Apache Spark™, a new product that addresses the challenges of adapting large scale array-based computing to the cloud and object storage while intelligently handling the full data management life cycle. If this is something that interests you, we’d love to hear from you. |
If this sounds all too familiar, then reading this article might be worth your while. The accepted general answer is to write a Python script (and use h5py [1]), but I am not going to repeat here what you know already. Instead, I will show you how to hot-wire one of the new shiny engines, Apache Spark [2], and make a few suggestions on how to reduce the coding on your part while opening the door to new opportunities.
But what about Hadoop? There is no out-of-the-box interoperability between HDF5 and Hadoop. See our BigHDF FAQs [3] for a few glimmers of hope. Major points of contention remain such as HDFS’s “blocked” worldview and its aversion to relatively small objects, and then there is HDF5’s determination to keep its smarts away from prying eyes. Spark is more relaxed and works happily with HDFS, Amazon S3, and, yes, a local file system or NFS. More importantly, with its Resilient Distributed Datasets (RDD) [4] it raises the level of abstraction and overcomes several Hadoop/MapReduce shortcomings when dealing with iterative methods. See reference [5] for an in-depth discussion.
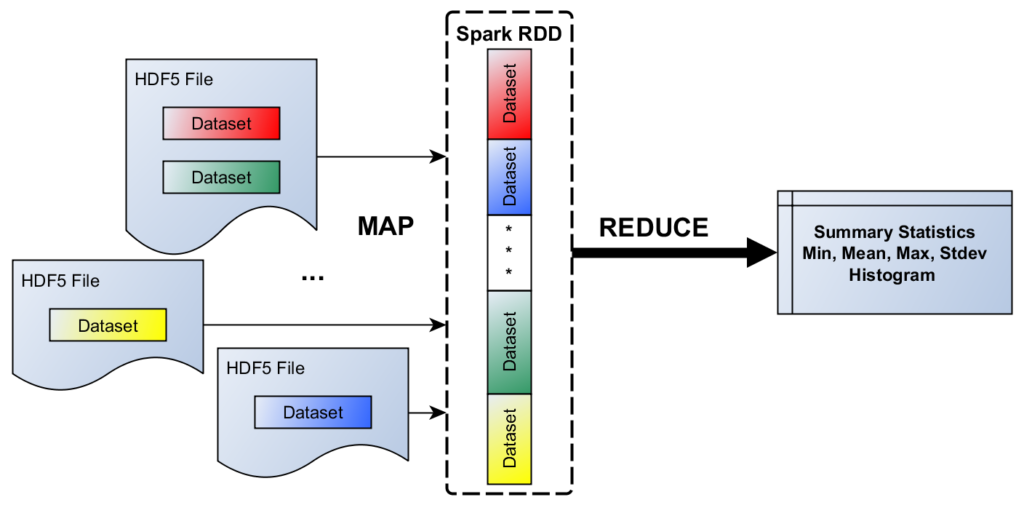
Figure 1. A simple HDF5/Spark scenario
As our model problem (see Figure 1), consider the following scenario:
Welcome, again, to the new HDF Blog. Let this be the beginning of a lively and informative dialogue....
The HDF Group’s mission is to provide high quality software for managing large complex data, to provide outstanding services for users of these technologies, and to insure effective management of data throughout the data life cycle....