Ted Habermann, The HDF Group
Fifteen years ago, NASA selected HDF as the format for the data products produced by NASA Satellites for the NASA Earth Observing System (EOS).
The HDF Earth Science Program is well aware of this important legacy. We focus on continuing support of U.S. environmental satellite programs (NASA Earth Observing System and Joint Polar Satellite System, JPSS), on-going quality assurance of the HDF libraries and helping data users access and understand products written in HDF. The HDF-EOS Information Center (#hdfeos) includes code examples in MATLAB, IDL, NCL, and Python, many driven by user questions. The site also provides information on other HDF tools.
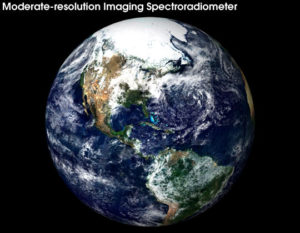
The Moderate Resolution Imaging Spectro-radiometer, MODIS, can see the Earth in true color as it appears from the satellite Terra. It also measures an unprecedented number of parameters related to global change including ocean plant life, cloud properties, atmospheric particulates (aerosols) and land surface change. Image courtesy NASA and the MODIS instrument team.
NASA’s decision ensured a role for HDF in Earth Science and set an important precedent. HDF developers, along with the U.S. and other Earth Observing nations, developed a clear distinction between Earth Science Data Objects (grids, swaths, profiles…); the metadata required to describe them; and the HDF objects (datasets, groups, attributes, etc.) that make them up.
The critical realization was that communities like EOS needed conventions for describing Earth Science objects to enable using and sharing those objects. These conventions, termed HDF-EOS, have been used successfully in hundreds of NASA products that can be easily shared among multiple users using standard tools.
Many other Earth Science communities have used the powerful combination of conventions and HDF.