Gerd Heber, The HDF Group
| Editor’s Note: Since this post was written in 2015, The HDF Group has developed HDF5 Connector for Apache Spark™, a new product that addresses the challenges of adapting large scale array-based computing to the cloud and object storage while intelligently handling the full data management life cycle. If this is something that interests you, we’d love to hear from you. |
“I would like to do something with all the datasets in all the HDF5 files in this directory, but I’m not sure how to proceed.”
If this sounds all too familiar, then reading this article might be worth your while. The accepted general answer is to write a Python script (and use h5py [1]), but I am not going to repeat here what you know already. Instead, I will show you how to hot-wire one of the new shiny engines, Apache Spark [2], and make a few suggestions on how to reduce the coding on your part while opening the door to new opportunities.
But what about Hadoop? There is no out-of-the-box interoperability between HDF5 and Hadoop. See our BigHDF FAQs [3] for a few glimmers of hope. Major points of contention remain such as HDFS’s “blocked” worldview and its aversion to relatively small objects, and then there is HDF5’s determination to keep its smarts away from prying eyes. Spark is more relaxed and works happily with HDFS, Amazon S3, and, yes, a local file system or NFS. More importantly, with its Resilient Distributed Datasets (RDD) [4] it raises the level of abstraction and overcomes several Hadoop/MapReduce shortcomings when dealing with iterative methods. See reference [5] for an in-depth discussion.
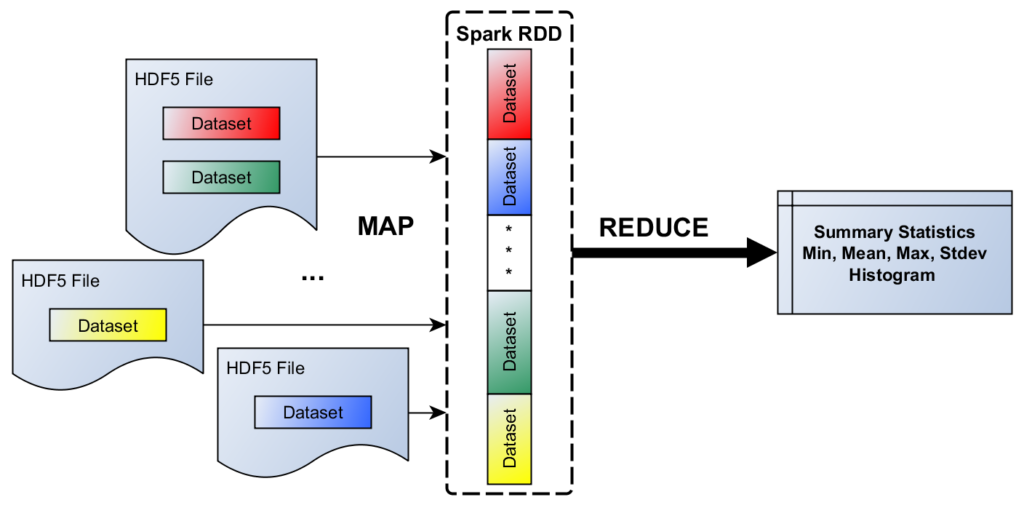
Figure 1. A simple HDF5/Spark scenario
As our model problem (see Figure 1), consider the following scenario:
 The 2015 HDF workshop held during the ESIP Summer Meeting was a great success thanks to more than 40 participants throughout the four sessions. The workshop was an excellent opportunity for us to interact with HDF community members to better understand their needs and introduce them to new technologies. You can view the slide presentations from the workshop here.
The 2015 HDF workshop held during the ESIP Summer Meeting was a great success thanks to more than 40 participants throughout the four sessions. The workshop was an excellent opportunity for us to interact with HDF community members to better understand their needs and introduce them to new technologies. You can view the slide presentations from the workshop here.